The Realm of Reinforcement Learning.
Welcome to a world of rewards.
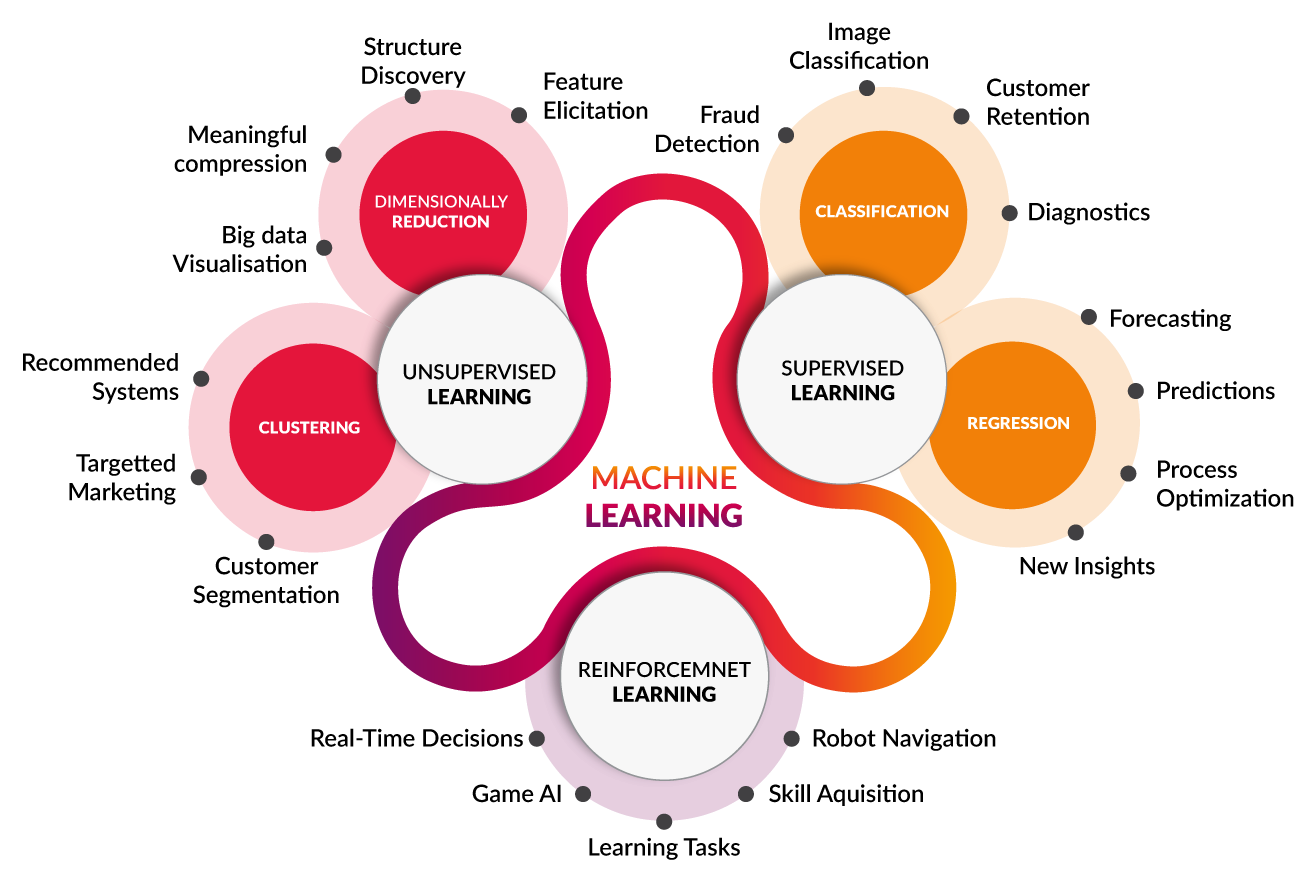
There are three types of machine learning the is supervised learning which makes use of a label and training data. Followed by unsupervised learning only the training data is required the is no need for a label. The algorithm uses either heuristics or hierarchical techniques to segments data into different clusters or centroids. Finally, the is reinforcement learning which is typically used for artificial intelligence gaming and robot navigation.
Each of the machine learning approaches have different applications. For example, supervised learning is used for forecasting, predictions and fraud detection. Within supervised learning there are two techniques namely classification and regression. The former is used for classifying data as the name suggests while the latter is used for predicting values. In the case of unsupervised learning there are also two techniques, one is used for customer segment and recommended systems. This technique is known as clustering, while other is called dimensionality reduction. It is used to compress data and visualise large volumes of data. Reinforcement learning on the other hand it has no subgroups that are distinguishable.
Reinforcement learning works based on a reward system and an environment, the interaction is performed by an agent in the form a function. It’s analogous to a child who is learning to understand a task by interacting with the environment. When I was younger my grandmother taught me how to count from 1 to 1000. The counting task was divided into three segments, the first set of numbers were 1 to 100. The first time I was able to count from 1 to 100 through trial and error I was rewarded some money to buy sweets. The reward motivated me to work in even harder before you know it, I was able to count from 1 to 1000.
Reinforcement learning works in a similar manner, the is an agent interacting with the environment. The agent is given a task to perform at a particular state. The state is intrinsic to the environment and it is time dependent. Whenever the agent does a task that is favourable it is rewarded with incentive similarly whenever the agent attains an undesirable outcome it is not rewarded. The reward-based approach encourages the agent to learning effectively and navigate environment using prior experience.
In this article reinforcement learning is explored and applied to a cartpole. The idea is to create and visualise a cartpole using cross entropy methods.
Reinforcement Learning Frameworks
Before the frameworks of reinforcement learning are studied, an understanding of the different algorithms is required. There is a plethora of RL algorithms but only a few are useful and applicable to everyday problems.
The is Deep Q Learning, to explain Deep Q-learning an understanding of Q-Learning is crucial. Q-Learning is a model free reinforcement learning algorithm it does not require adaptation to the environment. The agent knows exactly what to do and what action to perform in a given environment. Deep Q-Learning is an extension of Q-learning but the neural networks are used to find the approximate values known as Q-values.
Double DQN(Deep Q Network), is a combination of deep neural networks and Q-learning but compared to Deep Q learning, the approach uses two identical models. A model is required in this case no just one but two.
Deep Deterministic Policy Gradient, is a model free and a deterministic reinforcement learning algorithm with a policy-based approach. It uses the Bellman equation to determine the Q-function. The algorithm it is discrete in nature.
Cross Entropy Method uses Monte Carlo techniques to sample data and optimise a task. In RL it is used to train agents to perform a task.The above algorithms can be difficult to program from scratch but there are a number of frameworks that are used to solve a reinforcement learning problem. The frameworks are there to simplify the programming. The frameworks are listed below,
Keras-RL
OpenAI Baselines
Keras-RL
ACME
Keras-RL, is an ensemble of the state of the art deep reinforcement learning algorithms. The framework integrates to python through the keras library. While Stable Baselines uses OpenAI Baselines to implement the reinforcement (RL) algorithms. ACME is a framework that is designed for research-oriented algorithms.
Reinforcement Learning in action
In this article the Keras-RL framework is used to model a cart pole. The modeling of the cartpole is taken directly from the Keras-RL github page. The link is shown below,
To model the problem necessary libraries are needed, the screen print below shows the importing of the libraries,

There are a number of examples that can be modeled, from a pendulum to a cartpole. Since the cartpole is an area of interest, it is specified in the environment selection.

To model the problem the cross-entropy method is used. The screen print below shows model definition of a simple neural networks.

After defining the neural network, the cross-entropy method is compiled.

Fitting the model.

Once the model is fitted, the weights are saved and the end result is visualised.

The end result from the programming of the reinforcement learning cartpole is shown below,

The image is interactive when the output is a gif file. It oscillates from left to right.
Closing Remarks
There are many problems that can modeled using reinforcement learning. They are not limited to mechanics, for example a video game can be model around RL. Not much research is happening within RL when compared to other machine learning areas, there is a lot of potential in reinforcement learning.
The code used in article can be assessed through the following link,
You can follow and contact me on the following platforms,
Twitter :@blessing3ke
